
Als die American Standards Association (ASA) am 17. Juni des Jahres 1963 einen neuen Code (den ASCII-Code) für Informationsaustausch beschloss, waren Internet und PC noch Zukunftsmusik einiger Theoretiker.
Mehr als fünfzig Jahre nach dem Beginn des American Standard Code for Information Interchange (ASCII) beherrscht diese bescheidene 7-Bit-Kodierung noch immer weite Bereiche der Zeichensetzung in der Informationstechnik. Dieser Artikel erklärt Technik und Erfolgsgeschichte des ASCII-Standards.
Ein Standard entsteht: Die Anfänge des ASCII Codes
Anfang der 1960er Jahre stellte sich die Frage nach einem einheitlichen Kommunikationsformat für Teleprinter, die sich damals zunehmender Beliebtheit erfreuten.
Ein jeder neuer Standard musste die bisher von Teleprint-Systemen verwendeten alphabetischen, numerischen und grafischen Zeichen unterbringen. Grundlegende Frage für die American Standards Association war somit, wie viel mehr als diese 64 unentbehrlichen Zeichen untergebracht werden sollten.
Da bereits mit der Dezimalzahl 64 der 7-Bit Binärcode 1000000 erreicht war, kamen für den ASCII Code nicht weniger als 7 Bit infrage. Einige Mitglieder des Gremiums argumentierten, dass ASCII als 8-Bit-Code angelegt werden sollte, um so in 8 Bit zwei Sequenzen von je 4 Bit unterbringen zu können, was die Kodierung von zwei Dezimalziffern ermöglicht hätte.
Schließlich fiel die Entscheidung gegen die Nutzung eines weiteren Bits, das optional als Paritätsbit vorgesehen wurde. Dieses zusätzliche Bit konnte die Anzahl der mit 1 belegten Bits als gerade oder ungerade angeben, um so Übertragungsfehler aufdecken zu können.
Mit dem 7-Bit-Standard ASA X 3.4-1963 erhielt der ASCII Code seine erste offizielle Version. In dieser ursprünglichen Fassung waren noch 28 der 128 Positionen nicht belegt, was zu jener Zeit als ausreichende Erweiterbarkeit angesehen wurde. Tatsächlich erschien der Freiraum als so üppig, dass das Alphabet in Groß- und Kleinbuchstaben vertreten war.
Im Jahr 1963 kam es zur ersten kommerziellen Verwendung von ASCII. Die American Telephone & Telegraph’s verwendete es für ihr TeletypeWriter eXchange Netzwerk.
Spätestens mit dem Erlass von Präsident Johnson im Jahr 1968, in dem angeordnet wurde, dass sämtliche von der US-Regierung gekauften Computer den ASCII Code unterstützen müssen, war der Erfolg des Standards garantiert. Der rückblickend gering erscheinende Spielraum für Erweiterungen schuf eine bewegte Geschichte des Standards, die hier anhand der Struktur von ASCII weiter aufgezeigt wird.
Die Struktur des ASCII-Codes
Von den 128 Binärzahlen, welche vom ursprünglichen ASCII Code gefasst werden können, entsprechen 126 den Zeichen. Dabei kodiert schlicht eine binäre Sequenz von 7 Bit ein Zeichen. Diese Sequenzen werden häufig in hexadezimaler Schreibweise notiert. Ein Beispiel zeigt, warum.
Beispiel: Das Schriftzeichen A wird durch die Hexadezimalzahl 41 dargestellt. Binär ergäbe sich 1000001, was für Menschen erheblich schwieriger lesbar ist.
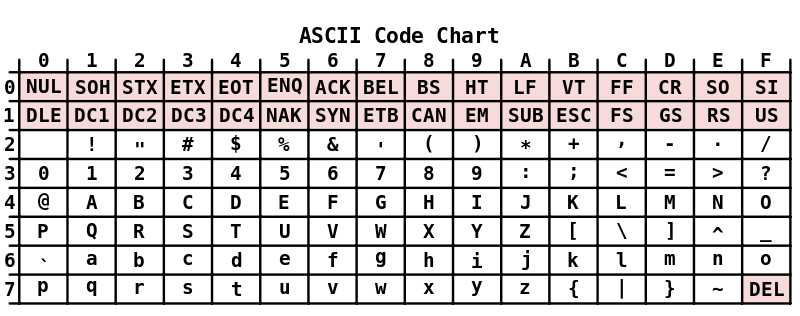
Elemente des Erfolgs: Bausteine ASCII-Codes
In seiner aktuellen Fassung (ANSI X3.4-1986) enthält der ASCII Code – angelehnt an die Tastatur der Remington Schreibmaschinen – die in westlichen Ländern gebräuchlichsten Schriftzeichen. Dies sind das Lateinische Alphabet in Groß- und Kleinschreibung, die arabischen Ziffern sowie Zeichen für Interpunktion und gängige Sonderzeichen.
Zu diesen 95 druckbaren Zeichen gesellen sich 33 nicht-druckbare Steuerzeichen wie z.B. der Zeilenvorschub. Ein Kuriosum stellt die Tatsache dar, dass das Leerzeichen als Sonderfall, der Tabulatorabstand aber als nicht-druckbar gewertet wird.
Steuerzeichen:
Die ASCII Codes von 00 (hex) bis 1F (hex) entsprechen den Steuerzeichen. Dazu gehören z.B. der Zeilenvorschub oder das Tabulatorzeichen. Nach diesen ersten beiden ASCII-Blöcken zu je 16 Zeichen, auch „ASCII-Sticks“ genannt, folgt das Leerzeichen an Position 20 (hex).
Die druckbaren Zeichen von ASCII:
Die druckbaren Zeichen belegen die Positionen 21(hex) bis 7E(hex):
|  !“#$%&'()*+,-./0123456789:;<=;>? |
| @ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_ |
| `abcdefghijklmnopqrstuvwxyz{|}~ |
Wie an der Tabelle ersichtlich ist, enthält der ASCII Code in seiner US-Amerikanischen Standardfassung keine Umlaute oder Varianten der lateinischen Zeichen.
Um Dezimalzahlen im 7-Bit-Code unterzubringen, erhalten sie das binäre Präfix 011, die folgenden 4 Bits codieren die Ziffern 1 bis 9. So ergibt sich beispielsweise für die Ziffer 9 der Binärcode 0111001.
Ein Relikt: Das Löschzeichen
An Position 7F (Binär 1111111) steht das Löschzeichen DEL. Es geht auf eine mechanische Besonderheit des Speicherns auf Lochkarten zurück. War ein Schreibfehler aufgetreten, konnte ein bereits gemachtes Loch nicht einfach wieder entfernt werden. Es blieb also nur die Option, alle 7 Bit zu lochen und damit auf 1111111 zu stellen. Diesem Block einen Inhalt in Form eines Zeichens zuzuweisen wäre unsinnig gewesen, da so jeder Fehler ein Zeichen oder einen Steuerbefehl produziert hätte.
Im Gegensatz zu 1111111 erhielt 0000000 ursprünglich keine Bedeutung, wurde jedoch später als Null-Byte in Programmiersprachen wie C verwendet, um das Ende eines Strings anzuzeigen.
Der ASCII-Code kommt auf den Computer
Der zunächst für Fernschreiber entwickelte ASCII Code bot sich mit Aufkommen der Computer als ressourcenschonende Zeichenkodierung für Drucker oder Bildschirmterminals an.
Um in dem nun weltweit verbreiteten ASCII einen einheitlichen Standard für Umlaute zu haben, wurde im Jahr 1983 das Internationale Alphabet 5 auf Basis des ASCII Codes mit der ISO-Nummer 646 als Norm eingetragen. Es enthielt 12 Zeichenpositionen, die umdefiniert werden konnten.
Da die Kodierung nun sprachspezifisch war, mussten Programmiersprachen sich auf jene Teile des Codes beschränken, der in allen Sprachen gleich war. Auf diese Zeit geht z.B. die Verwendung von < % statt { in C zurück.
Um derartige Probleme zu vermeiden und weitere Optionen einführen zu können, wurde das Paritätsbit häufig als Teil eines Bytes für Daten verwendet. Die in den 1960er Jahren verworfene Idee, den ASCII Code als 8-bit Standard zu etablieren wurde damit doch noch Realität, wenn auch ohne eine einheitliche Definition der zusätzlichen Stellen, was zu diversen untereinander inkompatiblen Varianten führte. Doch nicht nur neue Erweiterungen sondern auch Relikte aus der Teletype-Zeit schufen erhebliche Probleme.
Die Kunst des Umbruchs
Auf Teletext-Maschinen wurde eine neue Zeile durch zwei ASCII Code Befehle erreicht: Carriage return CR und Line Feed LF. Natürlich besteht auf einem Computer keine Notwendigkeit, den Druckkopf zurück an den Zeilenbeginn zu schicken, LF wäre also für den Zeilenumbruch völlig ausreichend.
Einige Betriebssysteme wie OS/8 oder RT-11 von DEC verwendeten weiterhin beide Befehle, während Macintosh oder ProDOS nur CR verwendeten. Mit zunehmender Vernetzung kam es dadurch zu Fehlern, die sich schon im Internetvorläufer ARPANET zeigten. Zur Lösung des Chaos trug das Telnet-Protokoll bei, das ein virtuelles ASCII-Terminal zur Kommunikation der Maschinen verwendete. Ermöglicht wurde dies durch das „Network Virtual Terminal“, einen einheitlichen Standard für die Übertragung mittels Telnet, auf den und von dem alle zu Telnet kompatiblen Anwendungen übersetzen mussten.
Noch heute besteht bei Unix-Betriebssystemen der Zeilenumbruch aus LF und bei Windows aus CR und LF. Das Telnet-Protokoll wurde später auch vom File-Transfer-Protocol FTP übernommen, das auch einen ASCII-Mode benötigt. Die Verwendung von NVT verhindert dabei durch die Übersetzung in für das jeweilige Betriebssystem richtige Zeichen das Zustandekommen von auf dem Zielsystem nicht verwendbaren Dateien, wie sie bei bitweiser Übertragung entstehen können.
Erweiterungen
Mit der weltweiten Verbreitung der Computertechnik wurden international an die jeweiligen Landessprachen und deren Zeichen angepasste ASCII Code Versionen entwickelt. Dabei handelte es sich um eine von Anfang an eingeplante Entwicklung, sollte doch ASCII nur eine nationale Variante eines internationalen Standards sein.
Die lokalen Sonderzeichen konnten nicht in allen Fällen in den anfänglich nicht belegten Bereichen des ASCII Codes untergebracht werden. Dadurch, dass Klammern dem nationalen Bereich zugeteilt waren, entwickelten sich verschiedenen Tastaturbelegungen. So ergab sich häufig der Fall, dass Umlaute getippt werden mussten, wo der Compiler Klammern berücksichtigen sollte. Wurde der Quelltext auf einem PC in einem anderen Land geöffnet, konnten statt Klammern andere Zeichen auftauchen. Wie so oft bei ASCII wurde auch hier ein Umweg gefunden: Die Programmiersprachen speichern den eingegebenen Text mittels Kürzeln, welche die Eindeutigkeit der Interpretation über verschiedene nationale Standards garantieren.
Besonders in der Frühzeit der Computertechnik beschritten manche Hersteller Sonderwege, so baute Commodore den PETSCII-Code seiner 8-Bit-Rechner auf ASCII 1963 statt auf der Version von 1967 auf.
Mit dem IBM-PC wurde die sehr erfolgreiche Code Page 437 eingeführt, welche die Kontrollzeichen durch grafische Symbole ersetzte und damit die Kompatibilität zu ASCII aufgab.
Kompatible Kodierungen zum ASCII-Code
Mit der Einführung von Computern, die für jedes Zeichen im Speicher ein 8-bit Byte verwendeten
, kam es zur Entwicklung von 8-Bit-Kodierungen auf der Basis des ASCII Codes, von denen viele das originale Mapping der Zeichen beibehielten, aber nach den ersten 128 weitere hinzufügten.Kodierungen mit fester Länge
Neben asiatischen Kodierungen, welche für die Darstellung eines Schriftzeichens zwei Byte benötigen, entstanden eine Reihe von zum ASCII Code kompatiblen Versionen. Im Folgenden sind die am weitesten verbreiteten Kodierungen aufgeführt.
ISO 8859 beinhaltet 15 auf dem ASCII Code aufbauende Zeichenkodierungen für:
- 1: Latin-1 Westeuropäisch
- 2: Latin-2 Mitteleuropäisch
- 3: Latin-3 Südeuropäisch
- 4: Latin-4 Nordeuropäisch
- 5: Kyrillisch
- 6: Arabisch
- 7: Griechisch
- 8: Hebräisch
- 9: Türkisch
- 10: Nordisch
- 11: Thai
- 12… wurde gestrichen
- 13: Latin-7 Baltisch
- 14: Latin-8 Keltisch
- 15: Latin-9 Westeuropäisch
- 16: Latin-10 Südeuropäisch
Windows-Codepages gibt es auf Basis von ASCII für folgende Sprachen:
- 874: Thai
- 932: Japanisch
- 936: Vereinfachtes Chinesisch
- 949: Koreanisch
- 950: Traditionelles Chinesisch
- 1250: Mitteleuropäisch
- 1251: Kyrillisch
- 1252: Westeuropäisch
- 1253: Griechisch
- 1254: Türkisch
- 1255: Hebräisch
- 1256: Arabisch
- 1257: Baltisch
- 1258: Vietnamesisch
Apple verwendet benannte Zeichensätze wie MacRoman
ISCII für indische Sprachen
Kodierungen mit variabler Länge
Um noch mehr Zeichen kodieren zu können und der schier unüberschaubaren Zahl verschiedener Kodierungen eine einheitliche Alternative entgegen zu setzen, wurde in den frühen 1990er Jahren mit dem Universal Character Set ein Standard entwickelt, der alle verbreiteten Schriftzeichen aufnehmen konnte. Dennoch löste Unicode in der Form des zu ASCII Code abwärtskompatiblen UTF-8 den ASCII Code erst im Dezember 2007 als am weitesten verbreitete Zeichenkodierung des Internet ab.
Neben Unicode gibt es noch eine Vielzahl weiterer Kodierungen mit variabler Länge, die auf ASCII aufbauen.
- ISO 6937 für Sprachen mit lateinischer Schrift
- EUC für ostasiatische Sprachen
- Big5 für traditionelles Chinesisch
- GB für vereinfachtes Chinesisch
 Halten Sie Ihre Software und Betriebssystem auf den aktuellsten Stand. Installieren Sie zeitnah neue Service Packs und Sicherheitsupdates.
Halten Sie Ihre Software und Betriebssystem auf den aktuellsten Stand. Installieren Sie zeitnah neue Service Packs und Sicherheitsupdates. Seien Sie aufmerksam beim Umgang mit E-Mails. Öffnen Sie keine unbekannten Dateiänhange und nehmen Sie sich in Acht vor
Seien Sie aufmerksam beim Umgang mit E-Mails. Öffnen Sie keine unbekannten Dateiänhange und nehmen Sie sich in Acht vor  Verwenden Sie ein
Verwenden Sie ein  Verwenden Sie eine Firewall, die den Netzwerkverkehr überwacht.
Verwenden Sie eine Firewall, die den Netzwerkverkehr überwacht.
hi hi meint
hallo